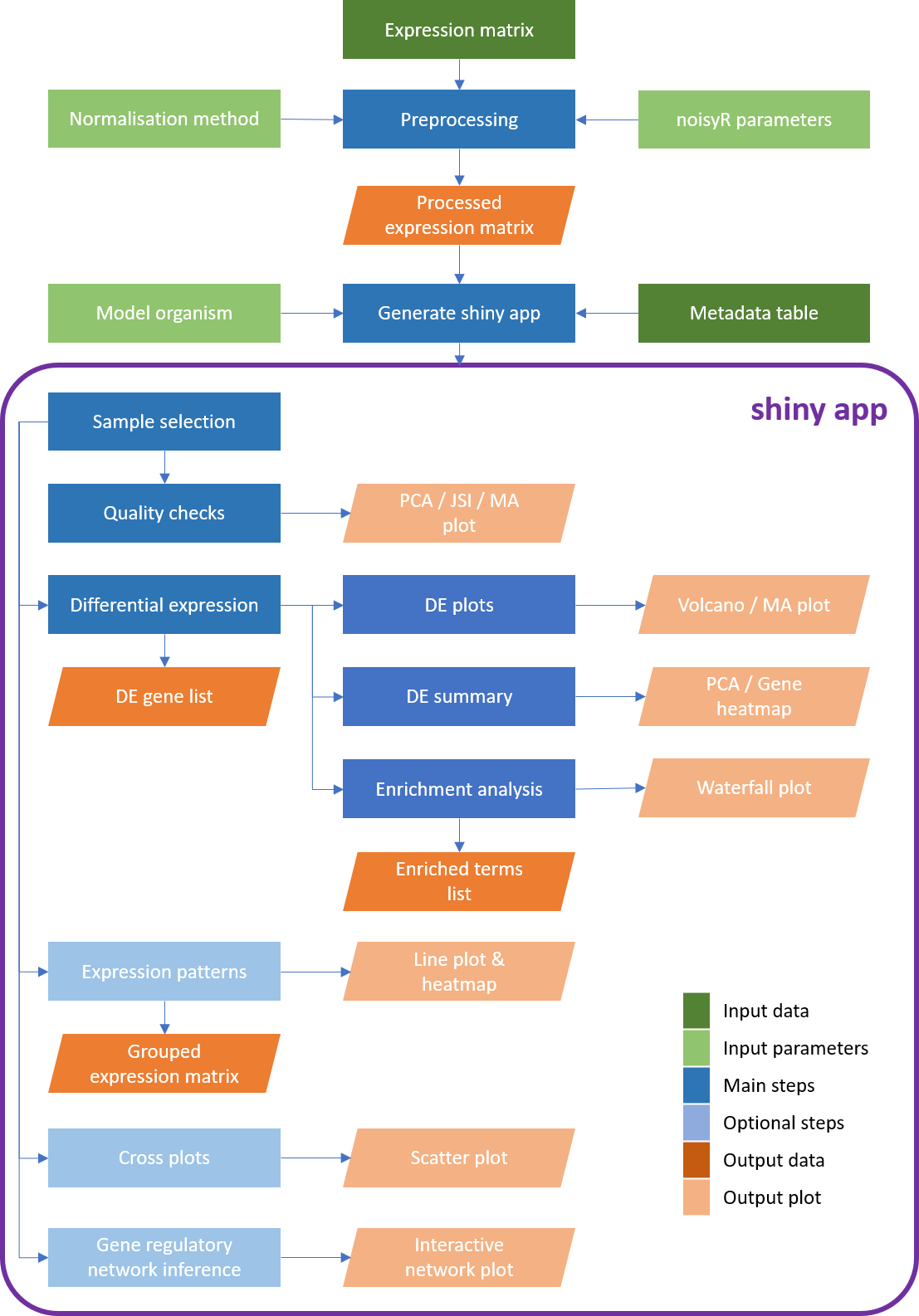
bulkAnalyseR: An accessible, interactive pipeline for analysing and sharing bulk sequencing results
Source:vignettes/bulkAnalyseR.Rmd
bulkAnalyseR.RmdBulk sequencing experiments are essential for exploring a wide range of biological questions. To bring the data analysis closer to its interpretation and facilitate both interactive, exploratory tasks and the sharing of (easily accessible) information, we present bulkAnalyseR an R package that offers a seamless, customisable solution for most bulk sequencing datasets. By integrating state-of-the-art approaches without relying on extensive computational support, and replacing static images with interactive panels, our aim is to further support and strengthen the reusability of data.
bulkAnalyseR enables standard analyses of bulk data, using an expression matrix as starting point. It presents the outputs of various steps in an interactive web-based interface, making it easy to generate, explore and verify hypotheses. The plots and tables generated can be easily downloaded and presented elsewhere. Moreover, the app can be easily shared and published, incentivising research reproducibility and allowing others to explore the same processed data and enhance the biological conclusions.
The example app described in this vignette can be found here
Installation
To install the package, first install all CRAN dependencies:
packages.cran <- c(
"ggplot2", "shiny", "shinythemes", "gprofiler2", "stats", "ggrepel",
"utils", "RColorBrewer", "circlize", "shinyWidgets", "shinyjqui",
"dplyr", "magrittr", "ggforce", "rlang", "glue", "matrixStats",
"noisyr", "tibble", "ggnewscale", "ggrastr", "visNetwork", "shinyLP",
"grid", "DT", "scales", "shinyjs", "tidyr", "UpSetR", "ggVennDiagram"
)
new.packages.cran <- packages.cran[!(packages.cran %in% installed.packages()[, "Package"])]
if(length(new.packages.cran))
install.packages(new.packages.cran)Then install bioconductor dependencies:
packages.bioc <- c(
"edgeR", "DESeq2", "preprocessCore", "GENIE3", "ComplexHeatmap"
)
new.packages.bioc <- packages.bioc[!(packages.bioc %in% installed.packages()[,"Package"])]
if(length(new.packages.bioc)){
if (!requireNamespace("BiocManager", quietly = TRUE))
install.packages("BiocManager")
BiocManager::install(new.packages.bioc)
}Finally, you can install the package from CRAN, or install the latest stable version of bulkAnalyseR from GitHub:
install.packages("bulkAnalyseR")
### OR
if (!requireNamespace("devtools", quietly = TRUE))
install.packages("devtools")
devtools::install_github("Core-Bioinformatics/bulkAnalyseR")Preprocessing
First, load bulkAnalyseR (plus dplyr and ggplot2 for convenience):
library(bulkAnalyseR)
library(dplyr)
##> Warning: package 'dplyr' was built under R version 4.1.2
##>
##> Attaching package: 'dplyr'
##> The following objects are masked from 'package:stats':
##>
##> filter, lag
##> The following objects are masked from 'package:base':
##>
##> intersect, setdiff, setequal, union
library(ggplot2)Loading an expression matrix
For this vignette we are using a subset of the count matrix for an experiment included in a 2019 paper by Yang et al. Rows represent genes/features and columns represent samples:
counts.in <- system.file("extdata", "expression_matrix.csv", package = "bulkAnalyseR")
exp <- as.matrix(read.csv(counts.in, row.names = 1))
head(exp)
##> SRR7624365 SRR7624366 SRR7624371 SRR7624372 SRR7624375
##> ENSMUSG00000102693 2 0 0 0 0
##> ENSMUSG00000051951 6 4 2 0 47
##> ENSMUSG00000102851 0 0 0 0 0
##> ENSMUSG00000103377 0 0 2 0 8
##> ENSMUSG00000104017 0 0 0 2 0
##> ENSMUSG00000103025 0 0 0 0 0
##> SRR7624376
##> ENSMUSG00000102693 0
##> ENSMUSG00000051951 37
##> ENSMUSG00000102851 1
##> ENSMUSG00000103377 6
##> ENSMUSG00000104017 2
##> ENSMUSG00000103025 3Defining metadata
The subset of the dataset we are using has samples from 3 timepoints: 0h, 12h and 36h, each with 2 biological replicates. We define a metadata table detailing which sample correspond to which timepoint:
meta <- data.frame(
srr = colnames(exp),
timepoint = rep(c("0h", "12h", "36h"), each = 2)
)
meta
##> srr timepoint
##> 1 SRR7624365 0h
##> 2 SRR7624366 0h
##> 3 SRR7624371 12h
##> 4 SRR7624372 12h
##> 5 SRR7624375 36h
##> 6 SRR7624376 36hThis metadata table should be a data frame containing at minimum two columns: the first column must contain the column names of the expression.matrix, while the last column is assumed to contain the experimental conditions that will be tested for differential expression.
Denoising and normalisation
Before using the expression matrix to create our shiny app, some preprocessing should be performed. bulkAnalyseR contains the function preprocessExpressionMatrix which takes the expression matrix as input then denoises the data using noisyR and normalises it (quantile normalisation by default, other methods can bespecified using the normalisation.method parameter). By specifying output.plot = TRUE, you can also print the expression-similarity line plots from noisyR to console and you can specify further parameters from the noisyR noisyr_counts.
exp.proc <- preprocessExpressionMatrix(exp, output.plot = TRUE)
##> >>> noisyR counts approach pipeline <<<
##> The input matrix has 38705 rows and 6 cols
##> number of genes: 38705
##> number of samples: 6
##> Calculating the number of elements per window
##> the number of elements per window is 3870
##> the step size is 193
##> the selected similarity metric is correlation_pearson
##> Working with sample 1
##> Working with sample 2
##> Working with sample 3
##> Working with sample 4
##> Working with sample 5
##> Working with sample 6
##> Calculating noise thresholds for 6 samples...
##> similarity.threshold = 0.25
##> method.chosen = Boxplot-IQR
##> Denoising expression matrix...
##> removing noisy genes
##> adjusting matrix
##> >>> Done! <<<
##> Performing quantile normalisation...
##> Done!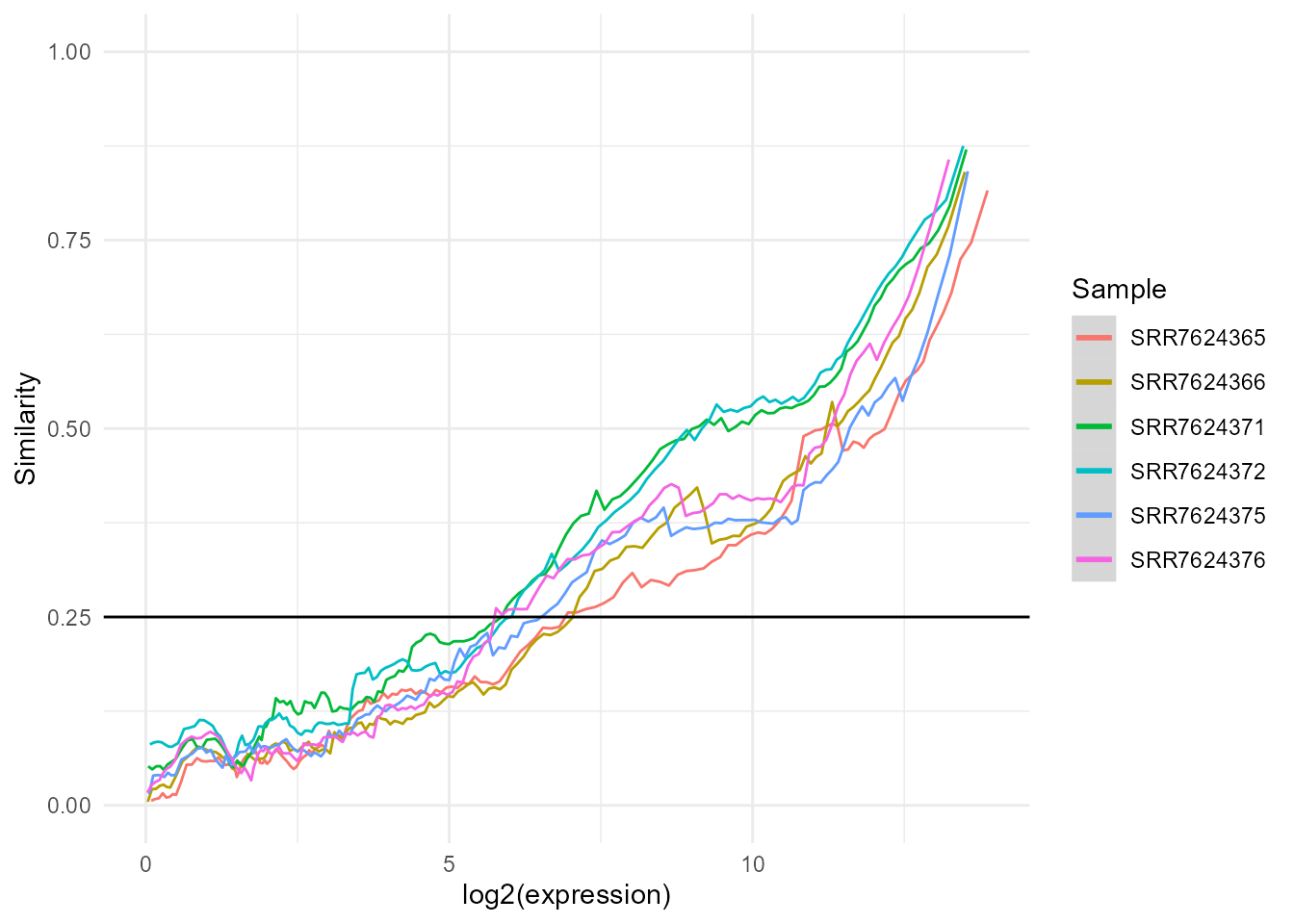
It is not recommended to use data which has not been denoised and normalised as input to generateShinyApp. You can also perform your own preprocessing outside preprocessExpressionMatrix.
Creating a shiny app
The example app for the Yang 2019 data can be found here. Readers are encouraged to try out the different features described below in the live version of the app to familiarise themselves with the different features.
The central function in bulkAnalyseR is generateShinyApp. This function creates an app.R file and all required objects to run the app in .rda format in the target directory. The key inputs to generateShinyApp are expression.matrix (after being processed using preprocessExpressionMatrix) and metadata. You can also specify the title of the app (which will appear in the navigation bar at the top of the app) with app.title, the modality (RNA by default) that will be displayed as the name of the main tab, the directory where the app should be saved with shiny.dir and the shiny theme you wish to use (‘flatly’ is the default, you can find the other options here). It is also recommended that you specify the organism on which your data was generated, firstly using the organism parameter using the gprofiler2 naming convention e.g. ‘hsapiens’,‘mmusculus’ (see here for the full list of organisms and IDs), and secondly specifying the database for annotations to convert ENSEMBL IDs to gene names e.g. org.Hs.eg.db - the full list of bioconductor packaged databases can be seen using this command:
BiocManager::available("^org\\.")The dataset in this example was generated on M. musculus so we would generate the app using this function call (note that the org.Mm.eg.db needs to be installed):
generateShinyApp(
shiny.dir = "shiny_Yang2019",
app.title = "Shiny app for visualisation of three timepoints from the Yang 2019 data",
modality = "RNA",
expression.matrix = exp.proc,
metadata = meta,
organism = "mmusculus",
org.db = "org.Mm.eg.db"
)If no organism is specified for g:profiler then the enrichment tab will be automatically excluded. If no model organism database is specified then the row names of the expression matrix will be used throughout. It is recommended to use ENSEMBL ids as the row names and supply the model organism through the org.db parameter if your organism is among the ones provided, to ensure compatibility.
This will create a folder called shiny_Yang2019 in which there will be 2 data files expression_matrix.rda and metadata.rda and app.R which defines the app. To see the app, you can call shiny::runApp(‘shiny_Yang2019’) and the app will start. The app generated is standalone and can be shared with collaborators or published online through a platform like . This provides an easy way for anyone to explore the data and verify the conclusions, increasing access and promoting reproducibility of the bioinformatics analysis.
By default, the app will have 10 panels: Home, Sample select, Quality checks, Differential expression, Volcano and MA plots, DE summary, Enrichment, Expression patterns, Cross plot, GRN inference. You can choose to remove one or more panels using the panels.default parameter.
generateShinyApp(
shiny.dir = "shiny_Yang2019_onlyQC_DE",
app.title = "Shiny app for visualisation of three timepoints from the Yang 2019 data",
modality = "RNA",
expression.matrix = exp.proc,
metadata = meta,
organism = "mmusculus",
org.db = "org.Mm.eg.db",
panels.default = c('QC','DE')
)An app that contains multiple modalities, different datasets, or different subsets of the same dataset can also be generated. The modality, expression.matrix, metadata, organism, org.db, and panels.default parameters are all vectorised and accept multiple arguments (a vector or a list if the original argument was more complex). Note that all these parameters must be the same length (or length 1) to avoid errors. An example of creating an app with two different versions of the original app created above is presented below:
generateShinyApp(
shiny.dir = "shiny_Yang2019_two_modalities",
app.title = "Shiny app for visualisation of three timepoints from the Yang 2019 data",
modality = c("RNA 1", "RNA 2"),
expression.matrix = exp.proc,
metadata = meta,
organism = "mmusculus",
org.db = "org.Mm.eg.db",
panels.default = list(
c("Landing", "SampleSelect", "QC", "DE", "DEplot", "DEsummary",
"Enrichment", "Patterns", "Cross", "GRN"),
c('QC','DE')
)
)See the following sections for more details about the default panels. For each panel, you can also find example code of how you could generate similar results or plots to the ones displayed in the panel without using the app.
Home
This tab contains some useful links (including this vignette!) to get you started with bulkAnalyseR.
Sample Select
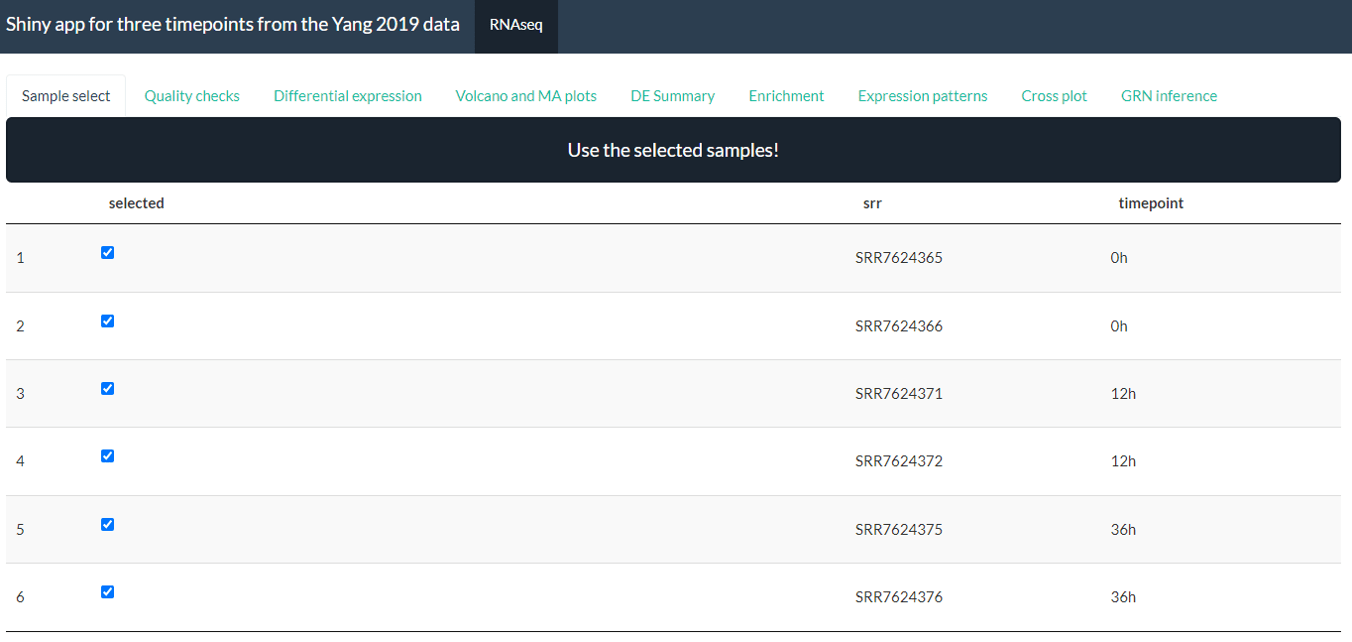
This tab allows you to select a subset of samples to use for the analysis. In particular this allows you to exclude low quality samples (which you could discover using QC tab) or focus on particular parts of the data. Once you have selected the samples you want, make sure to press the ‘Use the selected sample!’ button to confirm your choice. If you do not use this button or select samples then all samples will be used.
Quality check (QC)
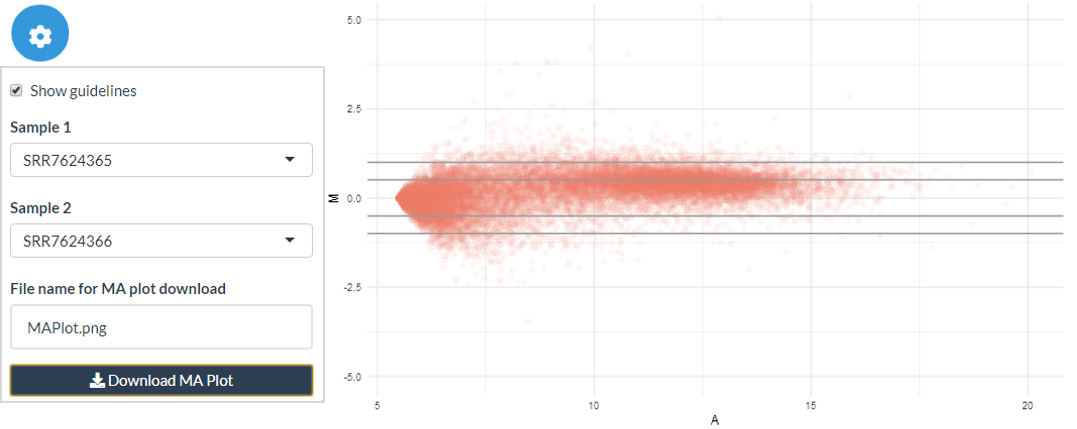
The Quality Check (QC) tab includes a Jaccard Similarity Index (JSI) heatmap, and a PCA dimensionality reduction, with groups based on the metadata information. This enables a high-level overview of the similarity across samples, usually reflecting the experimental design quite closely and serving as a sanity check. Within this panel, there is also the option to show the MA plot between any 2 columns - this can be used to further investigate any sample similarity or differences found through the JSI and PCA plots.
Jaccard Similarity Index
Within the JSI plot, you can change the order of samples using an ordering of metadata columns as well as specifying the number of top abundance genes that should be used to calculate the JSI. Finally, you can choose whether JSI values should be shown on the heatmap.
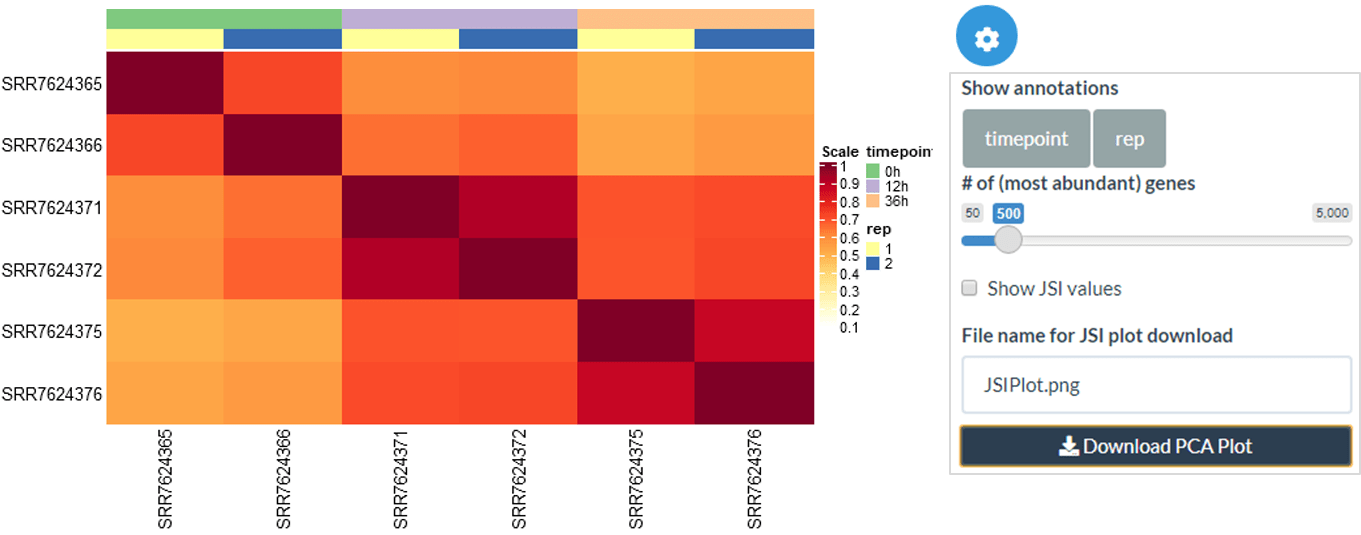
jaccard_heatmap(
expression.matrix = exp.proc,
metadata = meta,
top.annotation.ids = 2,
n.abundant = 500,
show.values = FALSE,
show.row.column.names = (nrow(meta) <= 20)
)PCA
The PCA plot can be created for a chosen number of top abundance genes and coloured by the metadata attribute selected. The sample labels and ellipses around groups can also be included or removed.
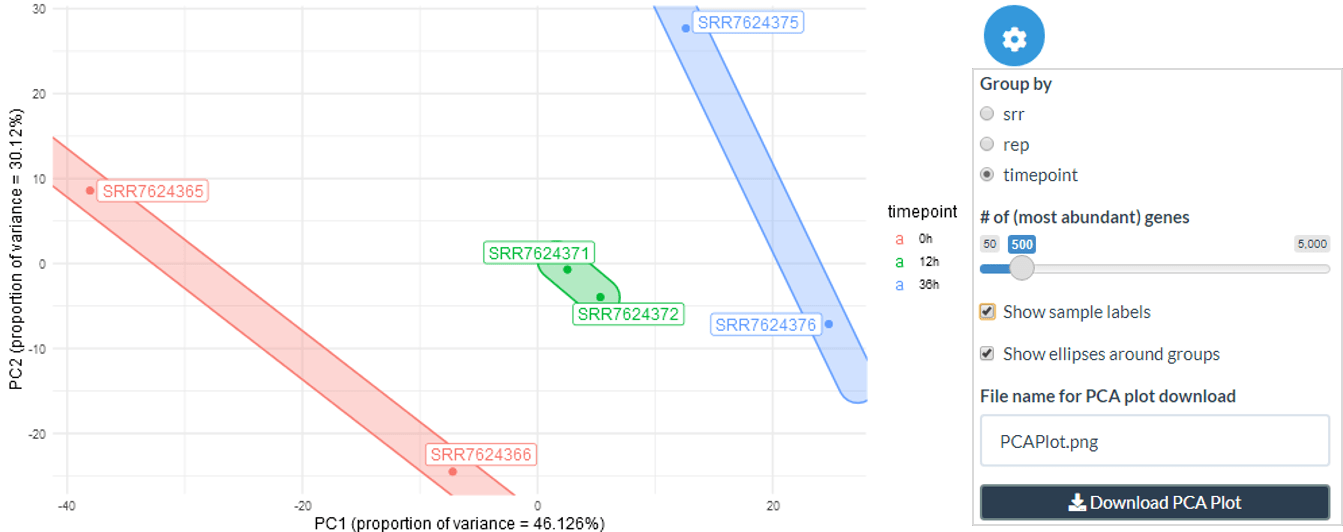
plot_pca(
expression.matrix = exp.proc,
metadata = meta,
annotation.id = 2,
n.abundant = 500,
show.labels = TRUE,
show.ellipses = TRUE
)
Differential expression (DE)
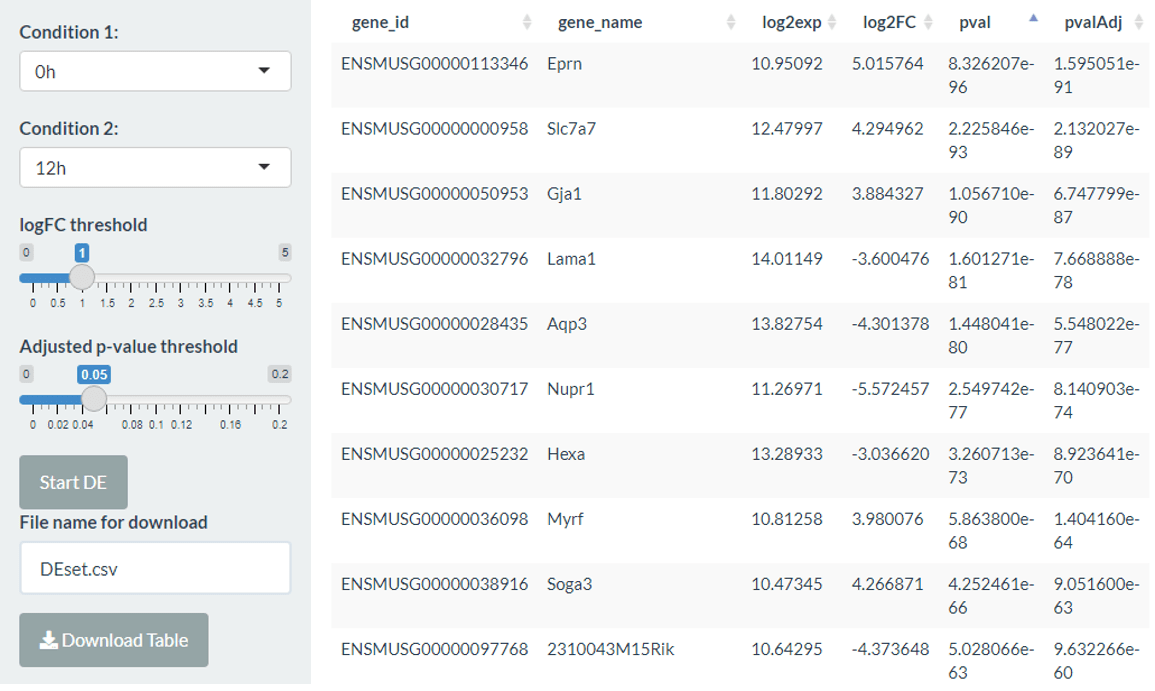
The differential expression (DE) tab can be used to compare any of the conditions from the columns of the metadata table using the edgeR or DESeq2 packages with customisable parameters (log2 fold change and adjusted p-value threshold). The output is a list of differentially expressed genes along with log2 fold changes and adjusted p-values. Within the app, the differentially expressed genes can be explored using an interactive table (sorted by absolute log2 fold change) and this can also be saved as a comma-separated file.
# first create annotation table
anno <- AnnotationDbi::select(
org.Mm.eg.db::org.Mm.eg.db,
keys = rownames(exp.proc),
keytype = 'ENSEMBL',
columns = 'SYMBOL'
) %>%
distinct(ENSEMBL, .keep_all = TRUE) %>%
mutate(NAME = ifelse(is.na(SYMBOL), ENSEMBL, SYMBOL))
DEtable <- DEanalysis_edger(
expression.matrix = exp.proc[, 1:4],
condition = meta$timepoint[1:4],
var1 = "0h",
var2 = "12h",
anno = anno
)
DEtable_deseq <- DEanalysis_deseq2(
expression.matrix = exp.proc[, 1:4],
condition = meta$timepoint[1:4],
var1 = "0h",
var2 = "12h",
anno = anno
)In this tab, you can also select genes of interest by clicking on the table, which can be used in the DE summary and Volcano/MA tabs. There is also a button to choose the top 50 DE genes (by absolute log2 fold change) or reset the selection.
Volcano/MA plots
Assuming differential expression has been performed, the Volcano/MA panel then visualises the DE genes, allowing interactive exploration of the data by searching for specific genes of interest or using the selected top DE genes and clicking on genes on the plot itself to gain more information and generate hypotheses.
Volcano plots
Volcano plots show log2 fold change against log10 BH-adjusted p-value. The DE points are shown in blue with their colour proportional to the log2 expression of the gene. Green and blue guide lines show the DE thresholds and twice the DE thresholds respectively.
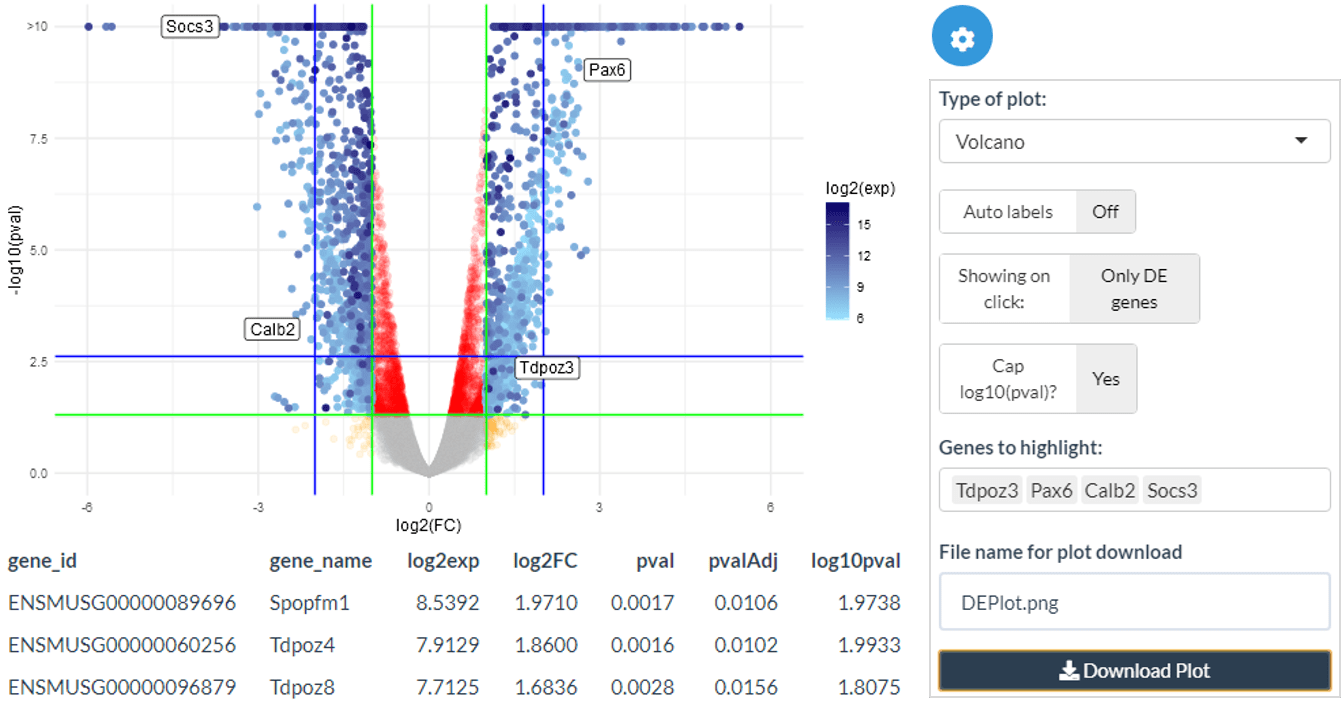
volcano_plot(
genes.de.results = DEtable,
pval.threshold = 0.05,
lfc.threshold = 1,
log10pval.cap = TRUE
)MA plots
The DE MA plots show log2 expression levels against log2 fold change for each gene. The DE points are shown in blue with their colour proportional to the log2 expression of the gene. Green and blue guide lines show the DE thresholds and twice the DE thresholds respectively.
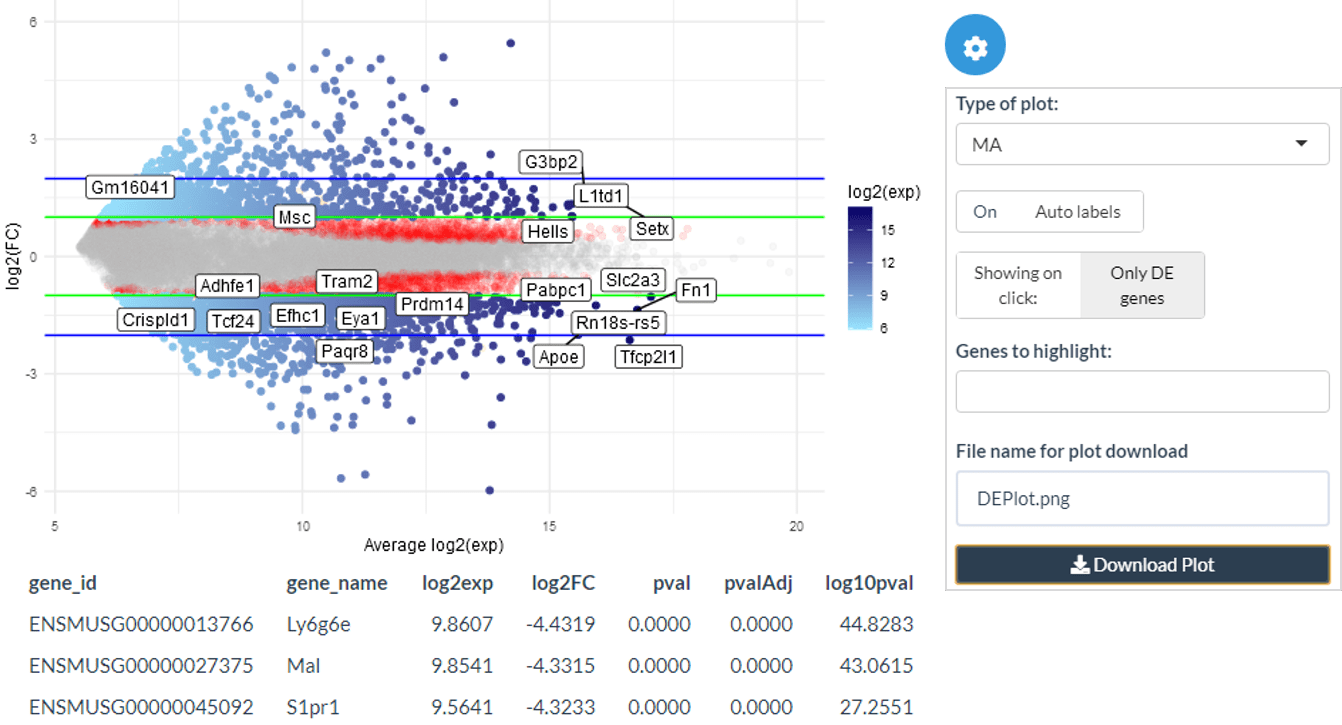
ma_plot(
genes.de.results = DEtable,
pval.threshold = 0.05,
lfc.threshold = 1
)DE summary
The DE summary panel allows further visualisation using the genes called DE or selected by the user in the DE panel.
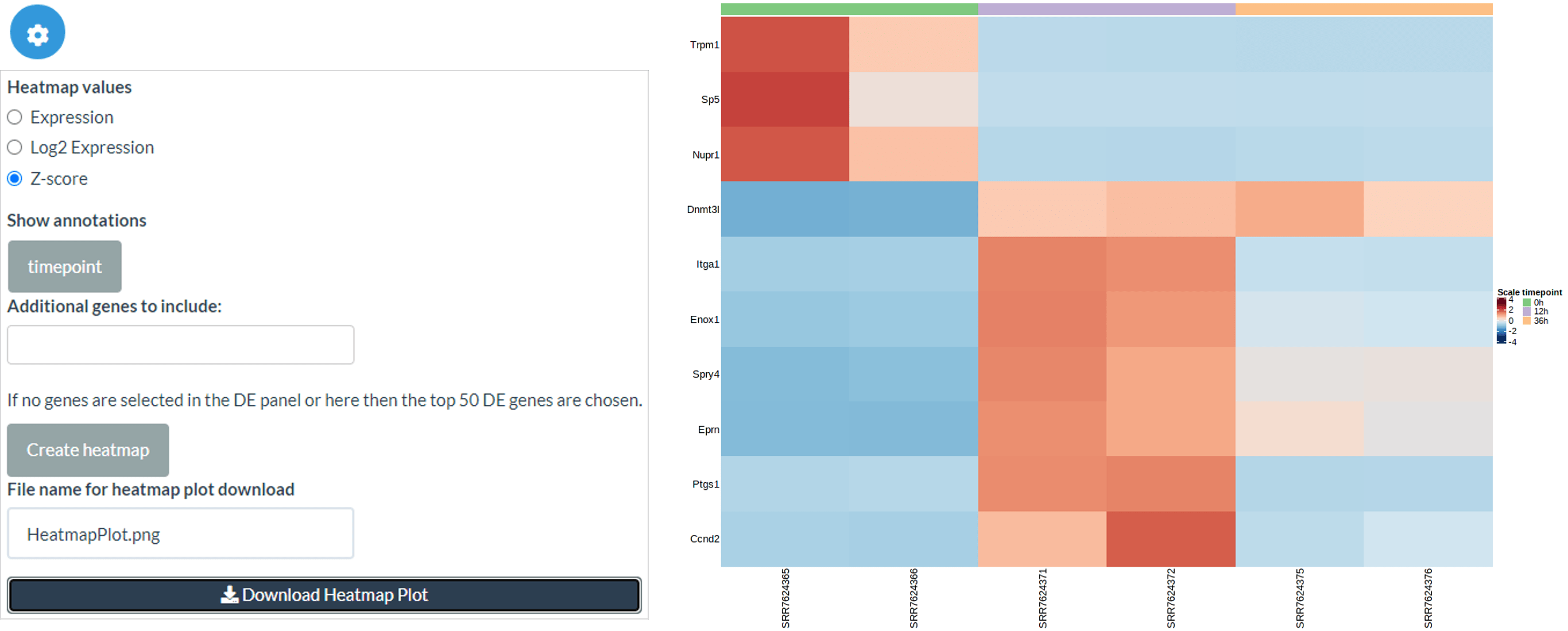
Expression heatmap
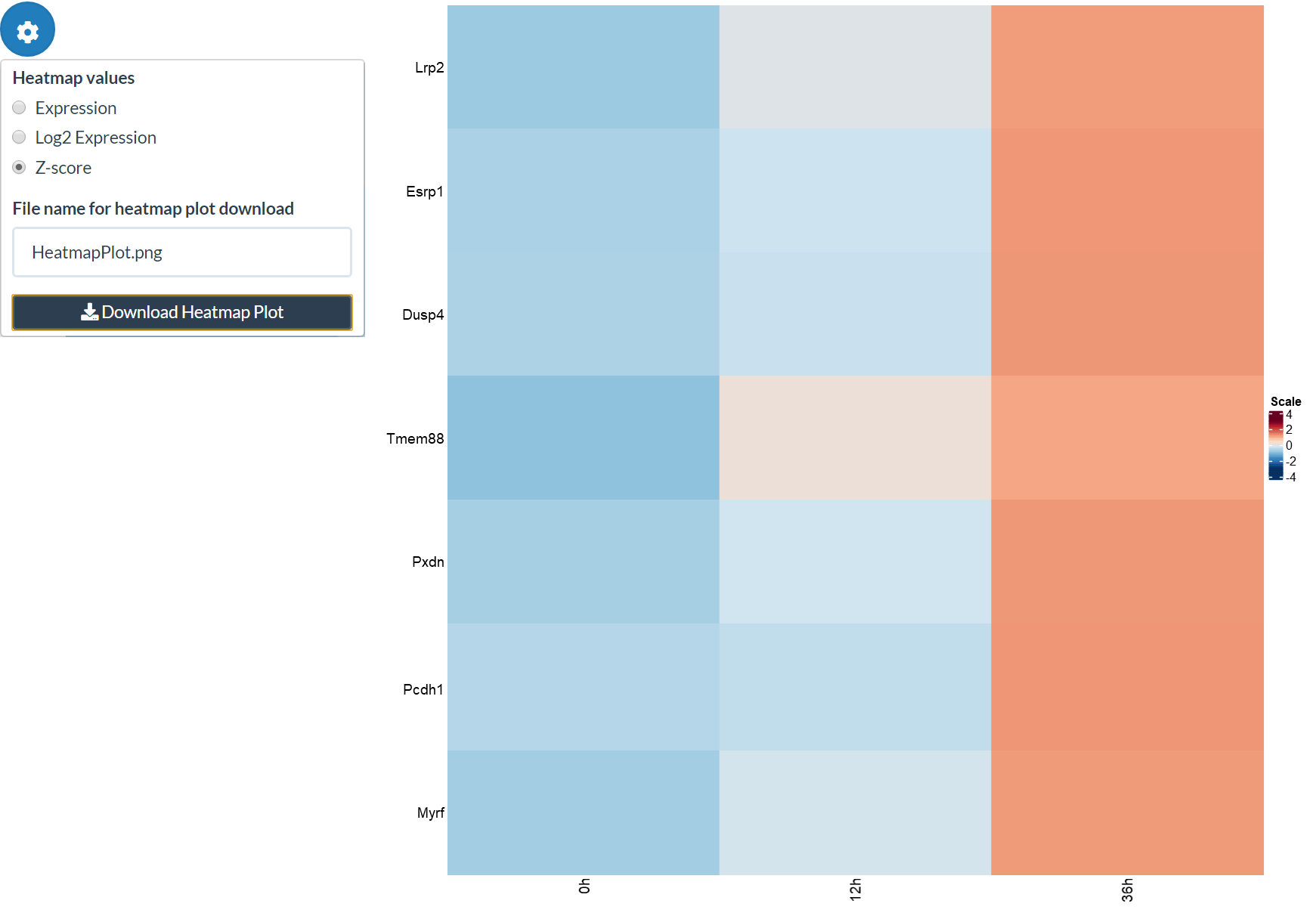
Secondly, we can create heatmaps for expression levels (raw expression level, log2 expression level or Z-score) of selected genes. By default the top 50 DE genes are used, but if users select genes in the DE panel then these are used instead. Also, further genes can be added by name in the Additional genes box. As in the JSI, you can change the order of samples using an ordering of metadata columns.
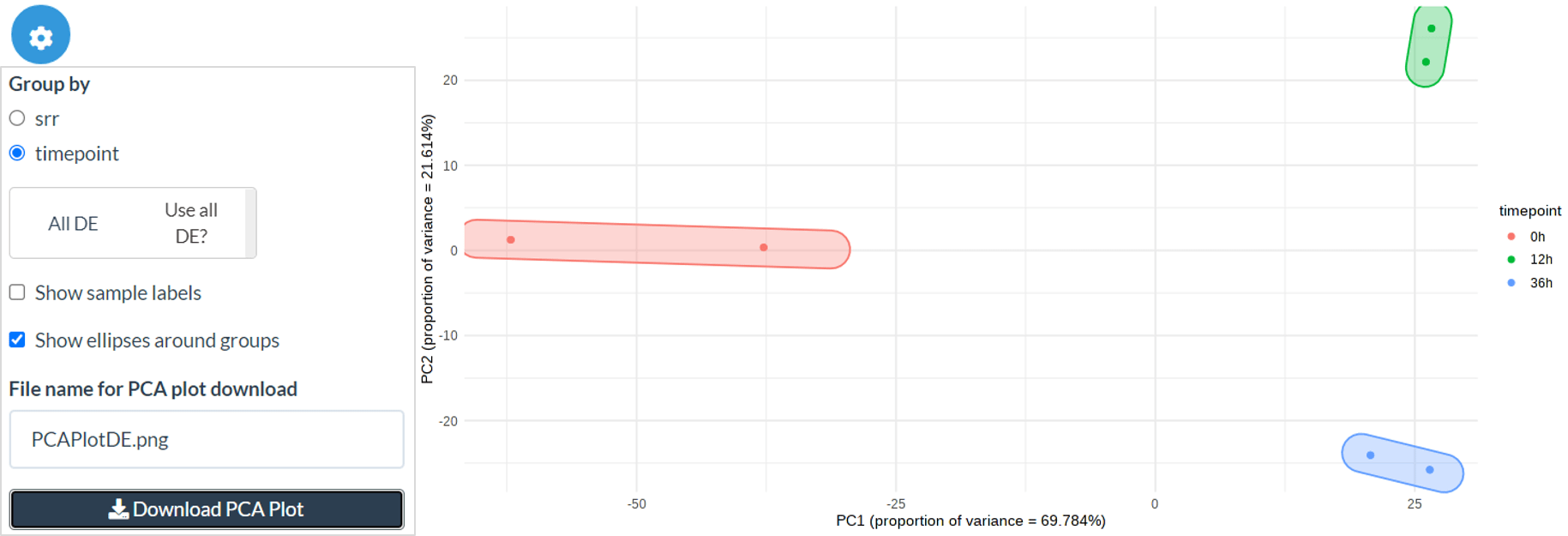
Post-differential expression PCA
Firstly, we can create a PCA using only the DE genes or using the selected genes from the DE panel. You can also create the PCA on only the user-selected DE genes by deselecting the ‘Use all DE?’ option. As in the QC PCA plot, you can colour points by your chosen metadata columns and add/remove sample labels and group ellipses.
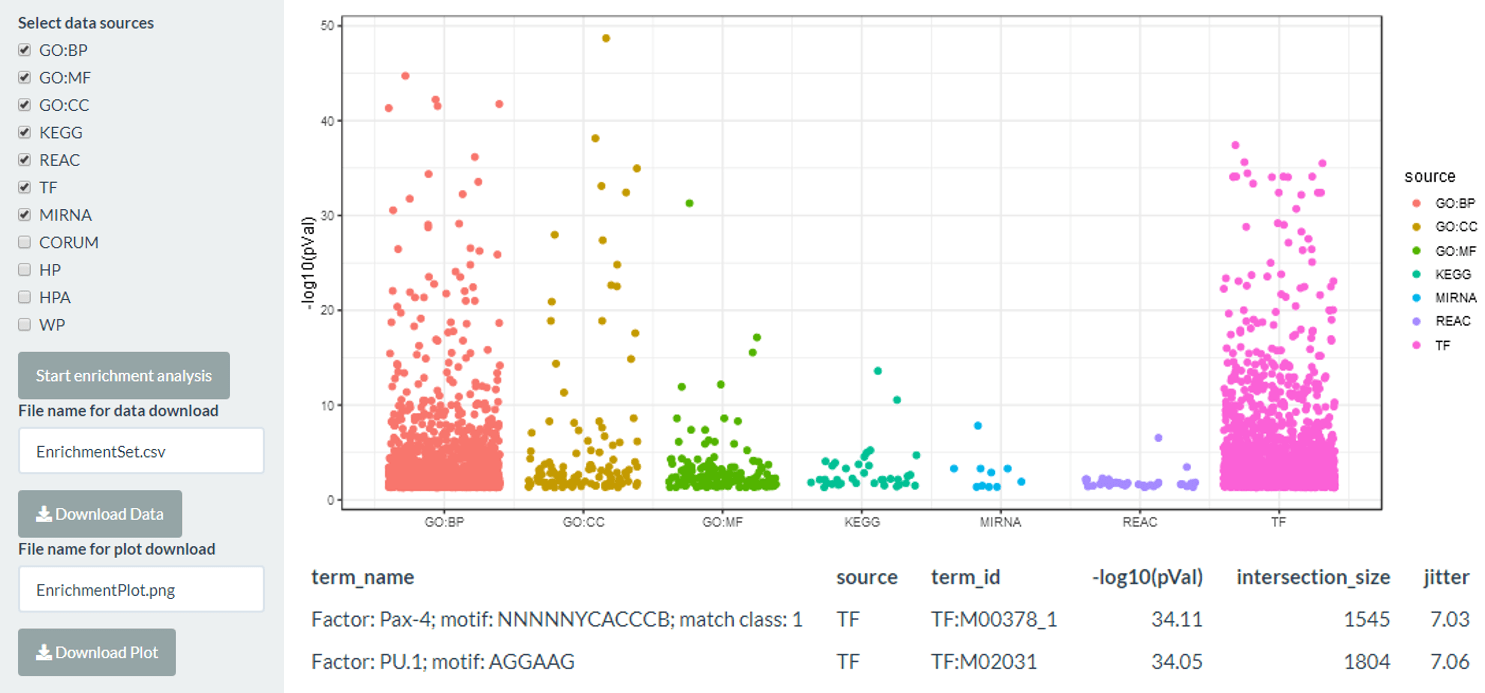
Enrichment
The enrichment tab uses the differentially expressed genes to run an enrichment analysis using g:profiler with a user selected output of the standard GO terms, the KEGG and reactome pathway databases, and miRNA and transcription factor lists. The plot shows the log10 BH-corrected p-value for each term, separated by category. The background set used is all the genes in the expression matrix - if noisyR preprocessing is used then this will be all the genes above the s/n threshold.
The output is both the results table from g:profiler which can be downloaded as well as a jitter plot which can be clicked to identify the most significant terms.
gostres <- gprofiler2::gost(
query = genes_de,
organism = "mmusculus",
correction_method = 'fdr',
custom_bg = DEtable$gene_id,
evcodes = TRUE
)
gostres$result <- mutate(
gostres$result,
parents = sapply(.data$parents, toString),
intersection_names = sapply(.data$intersection, function(x){
ensids <- strsplit(x, split = ",")[[1]]
names <- DEtable$gene_name[match(ensids, DEtable$gene_id)]
paste(names, collapse = ",")
})
)Expression patterns
The expression pattern tab allows the creation of expression patterns to identify potential genes of interest across a variety of conditions. The most common application of this is a time series, but it could be suitable for another logical progression between conditions. To define the series, the user must select a column of the metadata and drag states into the “Series of states to use” area.
The pattern identification is done by calculating a confidence interval for each gene in each condition, using all samples in that condition and the number of standard deviations away from the mean provided. The pattern between two consecutive conditions is defined as straight (S) if the intervals overlap and up (U) or down (D) if they don’t. The full expression pattern is the concatenation of individual patterns (for example, “UUS” for 4 conditions).
The grouped expression matrix can then be downloaded, showing which pattern each gene was assigned to. Plots are also created for the genes in the selected pattern (“Pattern to plot”).
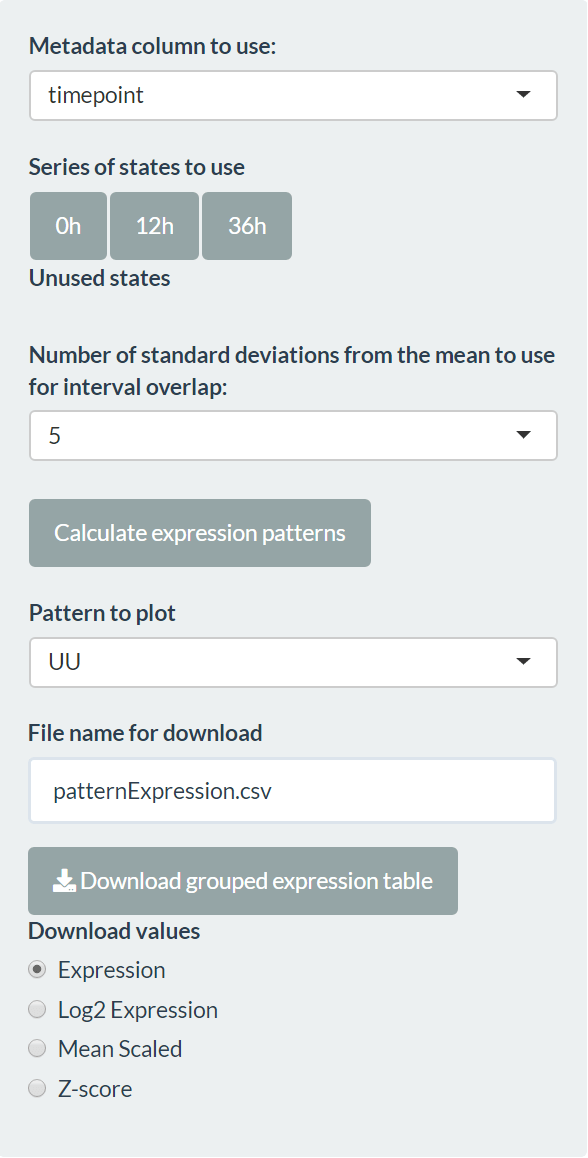
condition <- factor(meta$timepoint)
tbl <- calculate_condition_mean_sd_per_gene(exp.proc, condition)
patterns <- make_pattern_matrix(tbl, n_sd = 2)[, "pattern"]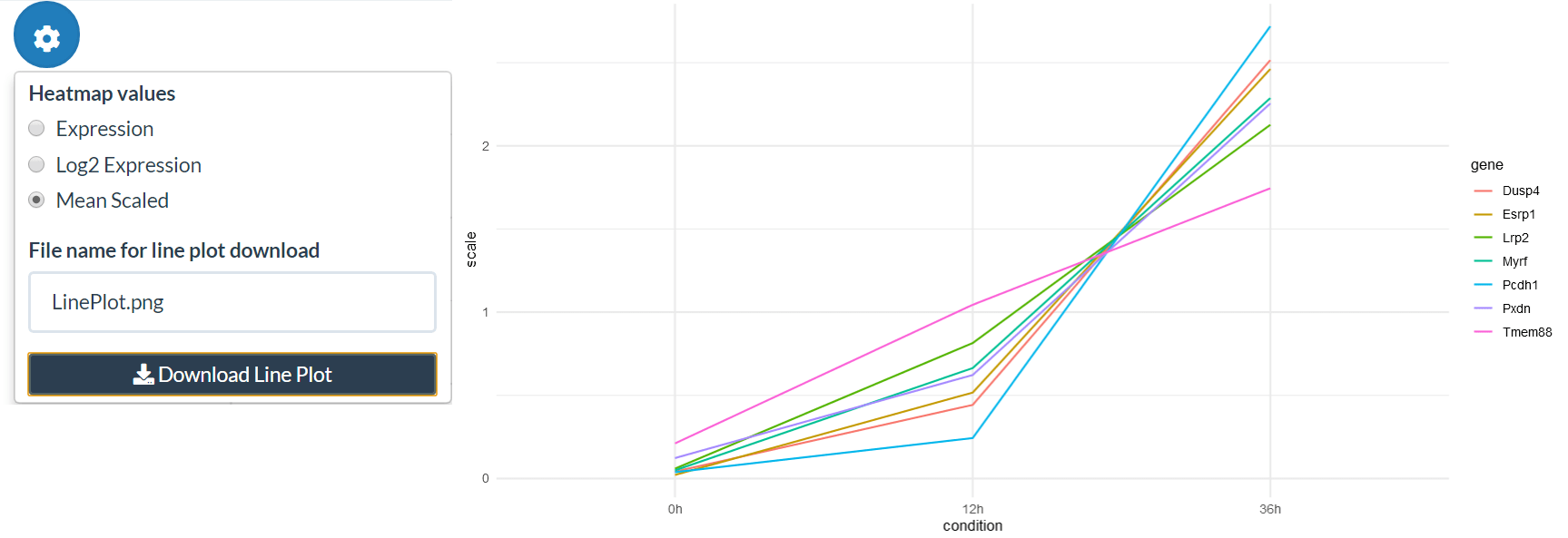
Cross plots
The cross plot tab allows you to compare two differential expression analyses against each other, for example two comparisons of interest or the same comparison using edgeR and DESeq2. The plot shows the log2 fold change of the two differential expression calls on each axis. Genes which are DE in both comparisons are coloured purple, in comparison 1 but not comparison 2 in blue and in comparison 2 but not comparison 1 in red. You can label selected genes and click on genes on the plot itself to gain more information and generate hypotheses.
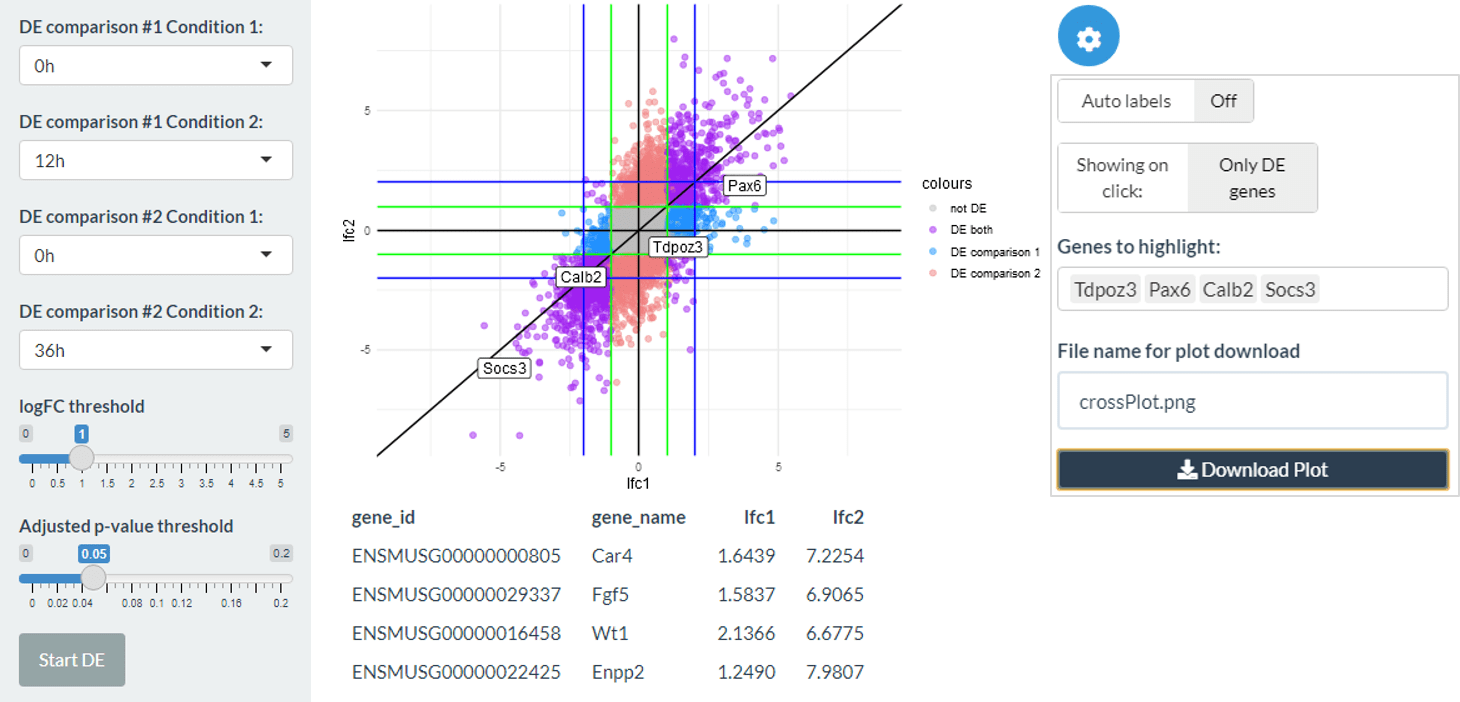
cross_plot(
DEtable1 = DEtable,
DEtable2 = DEtable_deseq,
DEtable1Subset = filter(DEtable, pvalAdj < 0.05, abs(log2FC) > 1),
DEtable2Subset = filter(DEtable_deseq, pvalAdj < 0.05, abs(log2FC) > 1),
lfc.threshold = 1
)Gene regulatory networks (GRN)
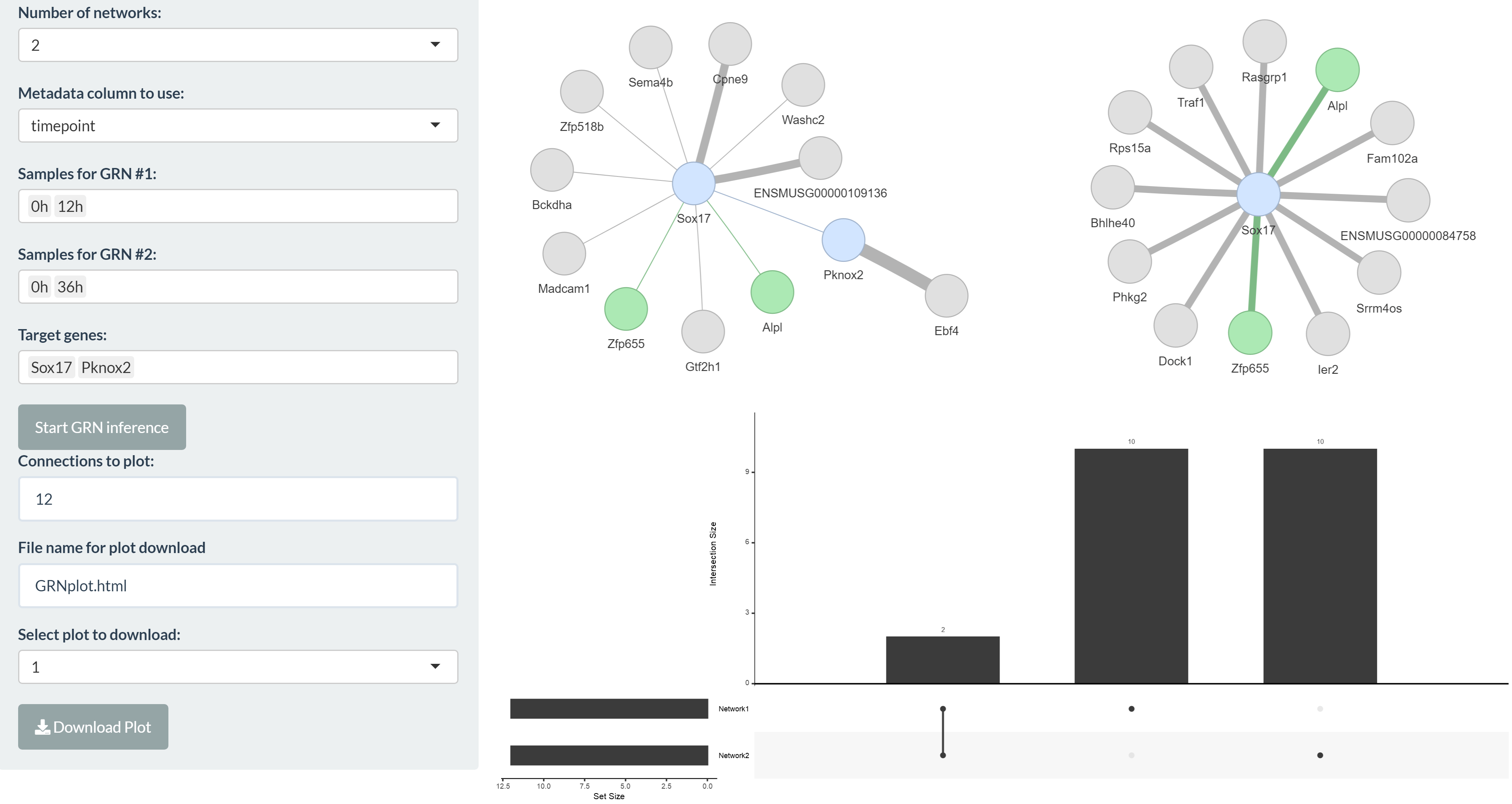
bulkAnalyseR enables the creation of small gene regulatory networks (GRNs) to facilitate further exploration and hypothesis generation based on genes of interest. Target genes can be selected and a small network with them as targets can be generated by clicking the “Start GRN inference” button. Within a bulkAnalyseR app, there are 2 separate tabs where inferred GRNs can be calculated and examined. Firstly, in GRN inference, up to four different GRNs can be inferred at once, to investigate differences between experimental conditions. If more than one GRN is generated, regulators in common are coloured differently and an UpSet plot is shown, summarising the commonalities of edges between the networks. Secondly, in the DE & enrichment GRN tab, a GRN can be inferred using only differentially expressed genes (using the comparison selected in the DE tab) and additional information relating these genes to transcription factors and/or miRNAs using results from the enrichment tab can be appended to the resulting network. In both cases, the number of regulators can then be adjusted and the network plots downloaded in interactive html format. Note that target genes can also regulate each other if the selected genes are functionally similar.
Adding extra panels
Alongside the default panels, you can also define your own panels and add them to the app. As an example, we could add an extra QC panel (in this case it will be exactly the same). Note that extra panels appear at the top level, and all parameters are converted to lists by generateShinyApp and thus need to be supplied as such. It might be useful to explore the app.R file generated by the command below to understand the structure:
generateShinyApp(
shiny.dir = "shiny_Yang2019_ExtraQC",
app.title = "Shiny app for visualisation of three timepoints from the Yang 2019 data - extra QC",
modality = "RNA",
expression.matrix = exp.proc,
metadata = meta,
organism = "mmusculus",
org.db = "org.Mm.eg.db",
panels.extra = tibble::tibble(
name = "RNA2",
UIfun = "modalityPanelUI",
UIvars = "'RNA2', metadata[[1]], NA, 'QC'",
serverFun = "modalityPanelServer",
serverVars = "'RNA2', expression.matrix[[1]], metadata[[1]], anno[[1]], NA, 'QC'"
)
)If you need to add extra data or package imports for the extra panel(s) then you can do this using the data.extra and packages.extra parameters. Make sure you have the extra data loaded when you create the app. Note that the data.exta object will be available in the app as a single list. For example:
extra.data1 = matrix(rnorm(36),nrow=6)
extra.data2 = matrix(rnorm(60),nrow=10)
generateShinyApp(
shiny.dir = "shiny_Yang2019_ExtraQC",
app.title = "Shiny app for visualisation of three timepoints from the Yang 2019 data - extra QC",
modality = "RNA",
expression.matrix = exp.proc,
metadata = meta,
organism = "mmusculus",
org.db = "org.Mm.eg.db",
panels.extra = tibble::tibble(
name = "RNA2",
UIfun = "modalityPanelUI",
UIvars = "'RNA2', metadata[[1]], NA, 'QC'",
serverFun = "modalityPanelServer",
serverVars = "'RNA2', expression.matrix[[1]], metadata[[1]], anno[[1]], NA, 'QC'"
),
data.extra = list(extra.data1, extra.data2),
packages.extra = "somePackage",
)
sessionInfo()
##> R version 4.1.1 (2021-08-10)
##> Platform: x86_64-w64-mingw32/x64 (64-bit)
##> Running under: Windows 10 x64 (build 22000)
##>
##> Matrix products: default
##>
##> locale:
##> [1] LC_COLLATE=English_United Kingdom.1252
##> [2] LC_CTYPE=English_United Kingdom.1252
##> [3] LC_MONETARY=English_United Kingdom.1252
##> [4] LC_NUMERIC=C
##> [5] LC_TIME=English_United Kingdom.1252
##>
##> attached base packages:
##> [1] stats graphics grDevices utils datasets methods base
##>
##> other attached packages:
##> [1] ggplot2_3.3.5 dplyr_1.0.8 bulkAnalyseR_1.0.0
##>
##> loaded via a namespace (and not attached):
##> [1] Rcpp_1.0.8.3 lattice_0.20-44 assertthat_0.2.1
##> [4] rprojroot_2.0.3 digest_0.6.29 foreach_1.5.2
##> [7] utf8_1.2.2 mime_0.12 R6_2.5.1
##> [10] evaluate_0.16 highr_0.9 pillar_1.8.1
##> [13] rlang_1.0.6 rstudioapi_0.14 jquerylib_0.1.4
##> [16] Matrix_1.5-1 preprocessCore_1.54.0 rmarkdown_2.16
##> [19] pkgdown_2.0.6 labeling_0.4.2 textshaping_0.3.6
##> [22] desc_1.4.2 splines_4.1.1 stringr_1.4.1
##> [25] munsell_0.5.0 philentropy_0.6.0 shiny_1.7.1
##> [28] compiler_4.1.1 httpuv_1.6.3 xfun_0.29
##> [31] pkgconfig_2.0.3 systemfonts_1.0.4 mgcv_1.8-36
##> [34] htmltools_0.5.2 tidyselect_1.1.2 tibble_3.1.6
##> [37] codetools_0.2-18 fansi_1.0.2 withr_2.5.0
##> [40] later_1.3.0 noisyr_1.0.0 grid_4.1.1
##> [43] nlme_3.1-152 jsonlite_1.8.0 xtable_1.8-4
##> [46] gtable_0.3.1 lifecycle_1.0.2 DBI_1.1.3
##> [49] magrittr_2.0.2 scales_1.2.1 cli_3.4.1
##> [52] stringi_1.7.6 cachem_1.0.6 farver_2.1.0
##> [55] fs_1.5.2 promises_1.2.0.1 bslib_0.4.0
##> [58] ellipsis_0.3.2 ragg_1.2.2 generics_0.1.3
##> [61] vctrs_0.3.8 iterators_1.0.14 tools_4.1.1
##> [64] glue_1.6.2 purrr_0.3.4 fastmap_1.1.0
##> [67] yaml_2.3.5 colorspace_2.0-3 memoise_2.0.1
##> [70] knitr_1.40 sass_0.4.1