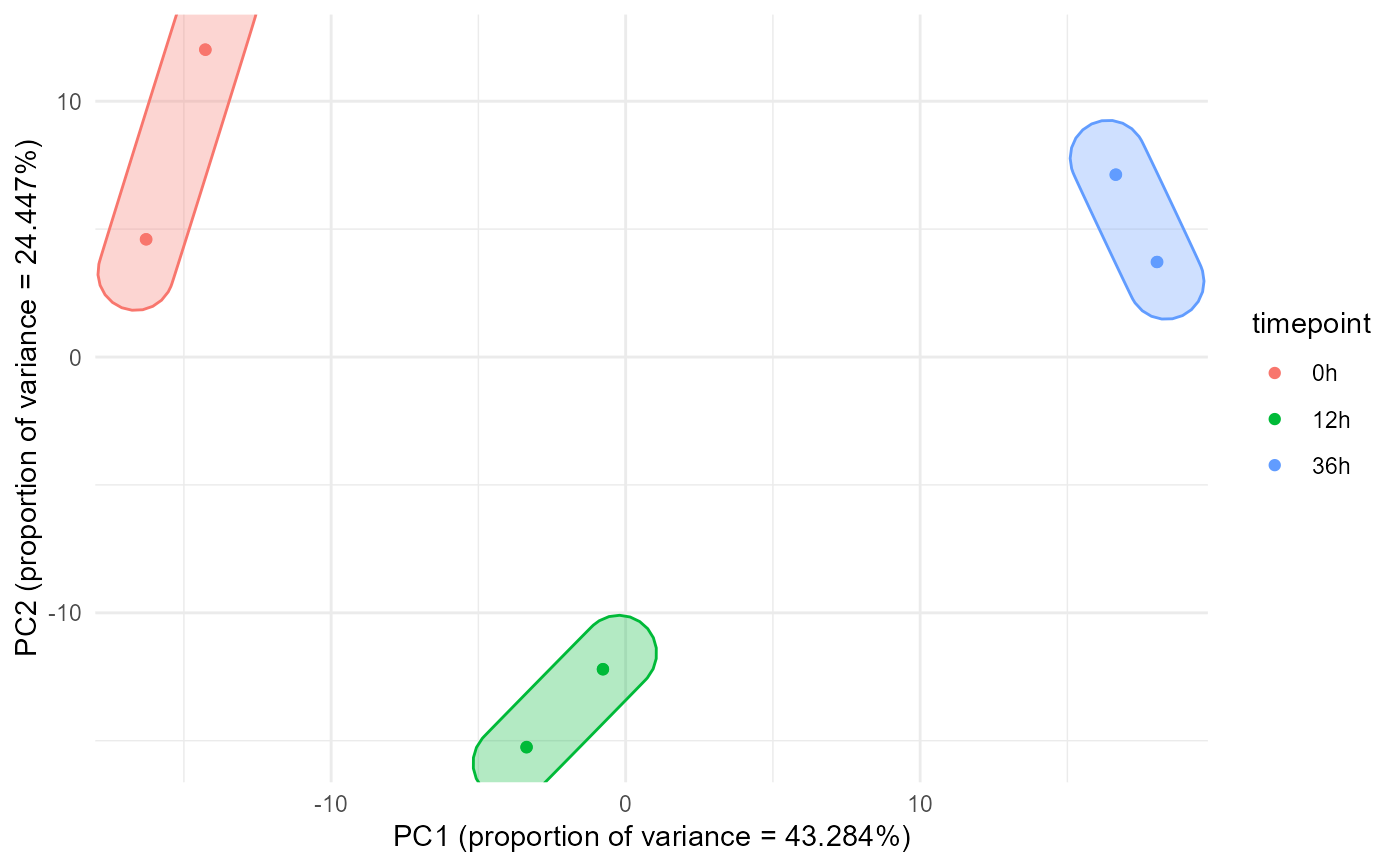
Create a principal component analysis (PCA) plot the samples of an experiment
Source:R/QCplotFuns.R
plot_pca.RdThis function creates a PCA plot between all samples in the expression matrix using the specified number of most abundant genes as input. A metadata column is used as annotation.
Usage
plot_pca(
expression.matrix,
metadata,
annotation.id,
n.abundant = NULL,
show.labels = FALSE,
show.ellipses = TRUE,
label.force = 1
)Arguments
- expression.matrix
the expression matrix; rows correspond to genes and columns correspond to samples; usually preprocessed by
preprocessExpressionMatrix; a list (of the same length as modality) can be provided if #'length(modality) > 1- metadata
a data frame containing metadata for the samples contained in the expression.matrix; must contain at minimum two columns: the first column must contain the column names of the expression.matrix, while the last column is assumed to contain the experimental conditions that will be tested for differential expression; a list (of the same length as modality) can be provided if #'
length(modality) > 1- annotation.id
a column index denoting which column of the metadata should be used to colour the points and draw confidence ellipses
- n.abundant
number of most abundant genes to use for the JSI calculation
- show.labels
whether to label the points with the sample names
- show.ellipses
whether to draw confidence ellipses
- label.force
passed to the force argument of ggrepel::geom_label_repel; higher values make labels overlap less (at the cost of them being further away from the points they are labelling)
Examples
expression.matrix.preproc <- as.matrix(read.csv(
system.file("extdata", "expression_matrix_preprocessed.csv", package = "bulkAnalyseR"),
row.names = 1
))[1:500,]
metadata <- data.frame(
srr = colnames(expression.matrix.preproc),
timepoint = rep(c("0h", "12h", "36h"), each = 2)
)
plot_pca(expression.matrix.preproc, metadata, 2)